
VMWare
Big Data and VMware
Big Data and VMware يعتبر هذا المقال من المقالات التى كنت احب ان اكتبة منذعدة شهور وتحديدا بعد الاعلان عن الاصدار الجديد VMware 5.5 والاعلان عن اسماء وتكنولوجيات غريبة كاضافات لل vSphere 5.5 وكان من ضمنها تطبيق يطلق علية Big Data فى البداية لم اهتم بالتطبيق الجديد لانى لم اجد له مصادر كافية للتعرف علية […]
Big Data and VMware
يعتبر هذا المقال من المقالات التى كنت احب ان اكتبة منذعدة شهور وتحديدا بعد الاعلان عن الاصدار الجديد VMware 5.5
والاعلان عن اسماء وتكنولوجيات غريبة كاضافات لل vSphere 5.5 وكان من ضمنها تطبيق يطلق علية Big Data
فى البداية لم اهتم بالتطبيق الجديد لانى لم اجد له مصادر كافية للتعرف علية حتى عند الشركة المنتجة له وانشغلت باشياء اهم منة خلال هذة الفترة
لكن الذى اعادنى للتفكير فى هذا التطبيق ليس VMware وانما تكنولوجيا ال Big Data فى حد ذاتها لانها تعتبر ثورة فى التكنولوجيا
وتكنولوجيا غائبة عنا ومجهولة للغالبية العظمى منا كمهندسين وحتى لمسئولى قواعد بيانات فى شركات كبيرة لم يسمعوا عن هذة التكنولوجيا
ومن اهمية هذة التكنولوجيا وقلة المعلومات عنها باللغة العربية احببت ان اعرفكم بها بنبذة بسيطة وسطحية لانى لست متخصص فيها ولكن على أمل ان يؤثر هذا الموضوع فى مهندسينا ويكون دفعة ولو بسيطة لهم بالبحث وتعلم هذة التكنولوجيا
لذلك فى مقالنا هذا سوف نعرف اولا بتكنولوجيا ال Big Data وبعد ذلك نرى ما هى علاقتها ب VMware

اولا : ما هى تكنولوجيا ال Big Data ؟
للاجابة عن هذا السؤال البسيط سوف نسال بعضنا البعض الاسئلة ونستعرض بعض القواعد المعروفة فى قواعد البيانات لكى نستطيع استيعاب معنى ال Big Data
كلنا لدينا Data خاصة بشركتنا باختلاف مجالها وحجمها هذة الداتا عبارة عن بيانات ولكى نستطيع ان نفهم هذة Data تحتاج اللى تنظيم لكى نستطيع ان نستخلص منها information ومن هذة المعلومات يصبح لدينا Knowledge
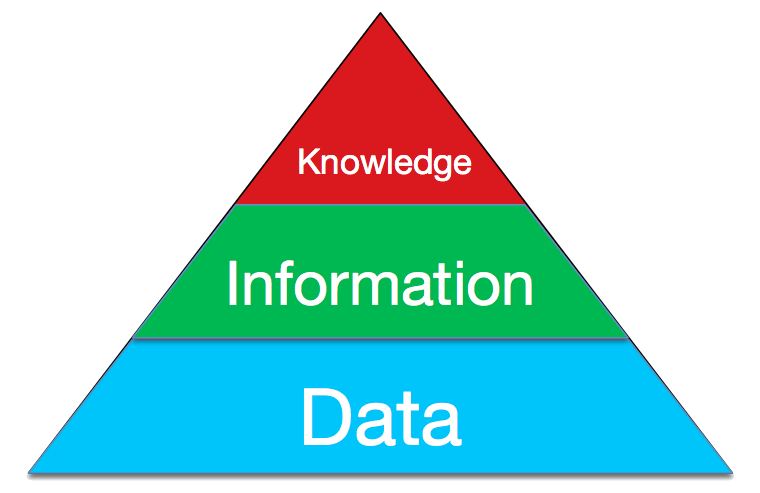
وهذا صورة لمراحل الداتا لدينا
كل الداتا فى العالم تمر على هذة المراحل للاستفادة منها والا تصبح داتا ليس لها اى قيمة ومهملة
لو تصورنا هذة الفكرة فى شركات ضحمة مثل Google , Yahoo and Facebook لديهم كمية داتا خرافية ويضاف اليها كميات ضخمة كل دقيقة
ويحب ان تقوم هذة الشركات بتصنيف هذة الداتا وتنسيقها لعرضها بشكل صحيح وبسيط للمستخدمين
على سبيل المثال جوجل لديه مليارات الصفحات يقوم بتجميعها وتحليل محتواها وتنسيقة وربطة بكلمات معينة لكى يكون جاهز لاى عملية بحث
تصوروا هذا العمل الضخم لان هذة الداتا حجمها خرافى كل يوم – فمثلا الانترنت ينموا كل يوم باحجام ضخمة تصل الى الف تيرا يوميا والارقام تتزايد كل يوم
وحتى بعيدا عن الانترنت فى الشركات والمراكز البحثية والفلك كلها لديها حجم داتا رهيب وتتزايد كل يوم هذة الداتا ولا يستطيعون ان يستفادوا منها الا بعد التحليل
لذلك وجد اننا فى حاجة الى تطبيق قوى يقوم بعملية تحليل لهذة الكمية الخرافية من الداتا خلال وقت معقول واتاحتها لنا بشكل بسيط وسهل للاستفادة منها
ويعرفون مصطلح ال Big Data انة عبارة عن تحليل وتنسيق داتا لا تستطيع ان تقوم بتنظيمها باستخدام تطبيقات قواعد البيانات المتعارف عليها فى وقت معقول
هنا يوجد تعريفات كثيرة فى العديد من المقالات وقياسات لاعتبار هذة الداتا تصنف على انها Big Data مثل مقياس ال Three VS
لكنى لا اريد ان نتعمق جدا فى المفاهيم الفنية لهذة الموضوع لان هدف المقال هو تعريف للتكنولوجيا فقط وبشكل بسيط
تكنولوجيا ال Big Data تعتبر حديثة ولم يتم البدء فى عملها الى فى عام 2005 من خلال اتنين من المهندسين العاملين فى شركة ياهو فى ذلك الوقت
وسموا هذا المشروع باسم Hadoop ومازال اسمة حتى الان بهذا الاسم ( جاء هذا الاسم من لعبة على شكل فيل كان يلعب بها احد ابناء احد المطورين لهذا التطبيق – وحتى الان شعارة على شكل فيل )
هذا المشروع مكتوب بلغة جافا بشكل اساسى وهو مفتوح المصدر ومتاح لكل الشركات وتتم رعايتة من قبل منظمة Apache المعروفة للمصادر المفتوحة
لذلك نجد كل شركات تكنولوجيا المعلومات الكبيرة قامت باخذ نسخ منة وقامت بالعمل عليها لحسابها ولدينا الان العديد من التوزيعات لهذة التطبيق تحت عدة مسميات مثل ال MapReduce – Hive – Pig
وايضا مشروع VMware Serengeti
حاليا جوجل وياهو ولينكدان وتوتير وفيس بوك وغيرها حتى الشركات الغير متخصصة فى ال IT تستخدم هذة التكنولوجيات مثل شركات طيران وشركات بيع تجزئة كبيرة
وحتى حكومات مثل نظام الرعاية الصحية فى امريكا ومشروع سيون الاوربى لابحات نشاة الكون ومشروع تحليل ال DNA البشرى وغيرها الكثير
حتى الان الموضوع جميل اننا امام تكنولوجيا تقوم بعمل تحليل وتنظيم كمية داتا ضحمة للاستفادة منها لكن ما الذى يميز هذة التكنولوجيا عن غيرها او بمعنى ادق كيف تعمل
هكون صريح معكم لانى لست متخصص فى عمليات قواعد البيانات واعتبر نفسى مستخدم بسيط لها فسوف يكون توضيح طريقة عملها بشكل بسيط على قدر فهمى لها
يكمن سر نجاح هذة التكنولوجيا فى اسلوب عملها
لان اسلوب علمها انك تقوم بتوزيع كميه الداتا الضخمة هذة على العديد من السيرفرات التى تعمل بنفس تطبيق تحليل المعلومات Hadoop وهو يقوم بعمل Node على كل سيرفر لدية ويقوم بتوزيع كمية معينة من الداتا على كل سيرفر وكل سيرفر يقوم بتحليل الداتا الموكلة الية ويقوم بارسالها الى التطبيق مرة اخرى فى شكل معلومات منظمة ومفهرسة ويقوم التطبيق بتجميعها من كل ال Nodes وتجميعها فى مكان واحد للمعلومات
هذا الاسلوب الرائع لا يمكن عملة من خلال قواعد البيات العادية لدينا مثل SAP or Oracle or SQL لانها لو قمنا بتوزيع الداتا على عدة سيرفرات كل سيرفر سوف يظهر نتائج الداتا الخاصة به منفصلة عن السيرفر الاخر ولا نستفيد من كل الداتا مرة واحدة
لذلك هذا الاسلوب قد نجح جدا مع الشركات الكبيرة بشكل رائع وكل العالم يتجة له الان ويوجد شركات اصبحت متخصصة فى تقديم هذة الحلول للشركات المتوسطة الغير متخصصة لتحليل الداتا الخاصة بها والاستفادة منها
ويوجد طلب كبير على المتخصصين فى هذة التكنولوجيا فى الخارج وقريبا سوف نرى لها مستخدمين فى عالمنا العربى ففرصة للمهتمين ان يقوموا بتعلم هذة التكنولوجيا من الان
وتقدم هذة التكنولوجيا الان باسلوب ال Cloud Computing عند شركة مثل Amazon AWS تقوم باعطائك العديد من السيرفرات التى يعمل عليها ال Hadoop بتوزيعها تختارها مناسبة لك لفترة زمنية معينه تقوم خلالها بتحليل كمية الداتا الضخمة لديك واخذ النتائج وتوقيف الخدمة
لكن اطيل اكثر من هذا فى هذا الموضوع لكى اتيح للمتخصصين ان يقوموا بالكتابة عنة اكثر وتعريف الناس به . لان هدفى هنا هو تعريف هذة التكنولوجيا للجميع لبدء الخطوة الاولى فى البحث لانى فى النهاية لست متخصص فى هذة التكنولوجيا ولن اكون متخصص فيها لانها بعيد عن مجالى الحالى – لذلك لو كان يوجد اى اخطا فى تعريف هذا التكنولوجيا فاعذرونى فقد حاولت بقدر الاستطاعة فهمها من خلال العديد من المقالات _ واتمنى ان ارى مقالات عربية وكورسات تشرح هذة التكنولوجيا قريبا
ثانيا : ما علاقة شركة VMware بتكنولوجيا ال Big Data ؟
من المعروف ان شركة VMware ليست من الشركات المتخصصة فى الداتا وليس لها تطبيقات تقوم بذلك
هوضح فى السطور التالية علاقتهم ببعض
كما قلت فى الاعلى ان كل الشركات دخلت سوق ال Big Data لكى تاخذ حصة فية وطبعا منهم شركة VMware ولية لا
لكن طبعا شركة VMware عملت شئ لتقديم هذا التكنولوجيا من خلال شئ هى ناجحة فية وهو ال VM
فقامت بعمل مشروع يسمى Serengeti هذا المشروع هو عبارة ان Virtual Machine تحتوى على عدة توزيعها من تطبيقات ال Hadoop , Hive وغيرها وتقوم بتقديم لك هذة ال Virtual Machine بشكل جاهز وبداخلها نظام تشغيل ومعدة للعمل بشكل مسبق

لن تحتاج الا ان تقوم باختيار التوزيعة وعدد ال VM وحجم الرامات والبروسيسور فى كل VM وسوف يقوم البرنامج بعمل لك عدة نسخ من هذة ال VM طبقا للعدد المطلوب وبنفس الحجم من الرامات والبرسيسور وبذلك يكون لديك خلال دقائق تطبيق ال Hadoop جاهز بدون ما يكون عندك دراية بكيفة اعدادة وايضا قام بعمل لك العديد من ال Node لتوزيع الداتا المراد تحليلها على العديد من السيرفرات لديك لتحليلها والوصول للنتائج خلال اقل فترة زمنية ممكنة
طبعا هتستفاد هنا من الكلاستر وال DRS وغيرها من خدمات VMware
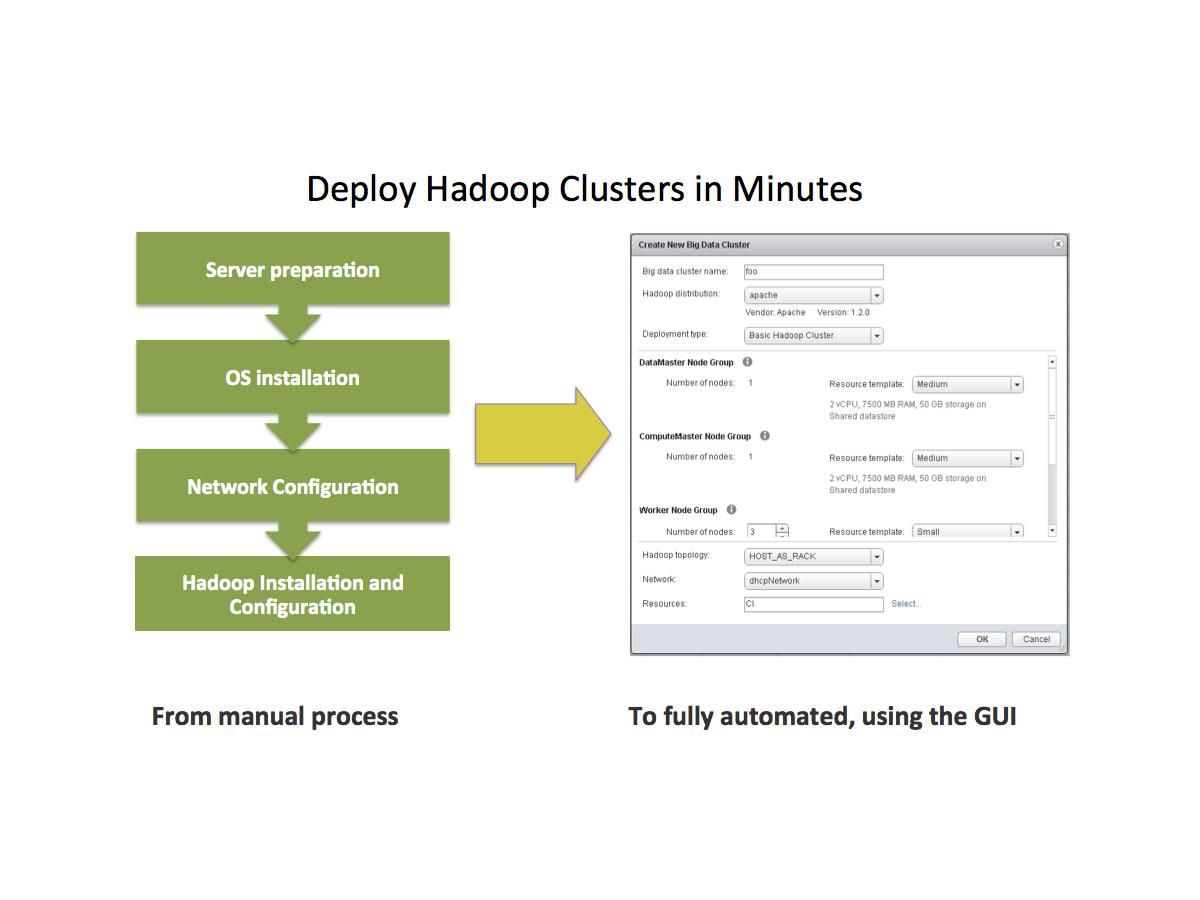
هذا التطبيق متاح حاليا من الاصدار vSphere 5.5 ويعمل فقط من خلال ال Web Client ويمكن تجربتة لمدة 60 يوم بشكل مجانى
لكن بالطبع سوف تحتاج الى بعض المعرفة بكيفية تشتغيل تطبيق ال Hadoop لان VMware تقوم بتقديمة فقط
واليكم بعض اللينكات له وبعض الكتب المجانية له والفيديو ايضا
http://www.vmware.com/products/vsphere/features-big-data
http://www.vmware.com/products/big-data-extensions
https://www.youtube.com/watch?v=FL_PXZJZUYg
https://www.youtube.com/watch?v=KMG1QlS6yag
فى النهاية ارجو الا اكون قد اطلت عليكم لكن احببت ان اعرفكم بهذة التكنولوجيا الغائبة عن الكثيرين والتى سوف يكون لها مستقبل قوى للغاية
وبالتوفيق للجميع
4 Comments